
🎯 Concept Focus BCP & DRP — From Risk Identification to Full Recovery
Business Continuity Planning (BCP) and Disaster Recovery Planning (DRP) are cornerstone processes for ensuring that an organization can withstand disruptions and resume operations as quickly and efficiently as possible. Both are tightly interwoven with risk management, but their scopes differ.
How BCP Ties Into Risk Management
The path from identifying risks to establishing continuity measures generally follows this sequence:
Potential Risks → Risk Assessment → Identified Risks → Security Controls → Residual Risks → Contingency Plan
Risk Management focuses on reducing risk exposure to acceptable levels.
BCP ensures that essential business operations can continue even when risks materialize.
A clear understanding of the differences between potential, identified, and residual risks is essential for designing effective plans.
Understanding Risk Types
a) Potential Risks
The starting point in risk planning — these are the threats an organization could face:
Natural: Earthquakes, floods, hurricanes, extreme weather events.
Human: Employee mistakes, insider threats, deliberate acts of sabotage.
Technological: Cyberattacks, system or hardware failures, data breaches.
b) Risk Assessment
Once potential risks are listed, a structured evaluation determines the likelihood and impact of each risk. This helps decide which threats must be addressed first.
c) Identified Risks
Risks that remain after the assessment — still categorized into natural, human, and technological types.
Security Controls for Risk Mitigation
When risks are known, organizations apply controls to reduce either their likelihood or their impact. These fall into three categories:
Management Controls — Strategic measures such as policies, documented procedures, and training.
Operational Controls — Daily activities like implementing access restrictions, system monitoring, and backup routines.
Technical Controls — Tools and technologies such as firewalls, encryption mechanisms, and intrusion detection systems.
Residual Risks
Even with strong controls in place, some risk remains. These residual risks exist across all three categories and must be addressed through contingency planning.
Contingency Planning & Incident Response
Contingency Planning defines how the organization will recover and maintain operations after an incident.
The Incident Response Plan (IRP) is part of this strategy, detailing the immediate steps to take during an incident — from detection and containment to initiating recovery.
A well-prepared organization responds to disruptions methodically, avoiding the chaos of ad-hoc decisions.
BCP vs DRP — Where They Differ
BCP (Business Continuity Plan): A broad plan covering the entire organization — all business processes, critical operations, IT recovery, and any other measures to keep essential services running.
DRP (Disaster Recovery Plan): A specialized subset of BCP focused solely on IT systems, data, and infrastructure recovery.
Image Courtesy : ArcticWolf
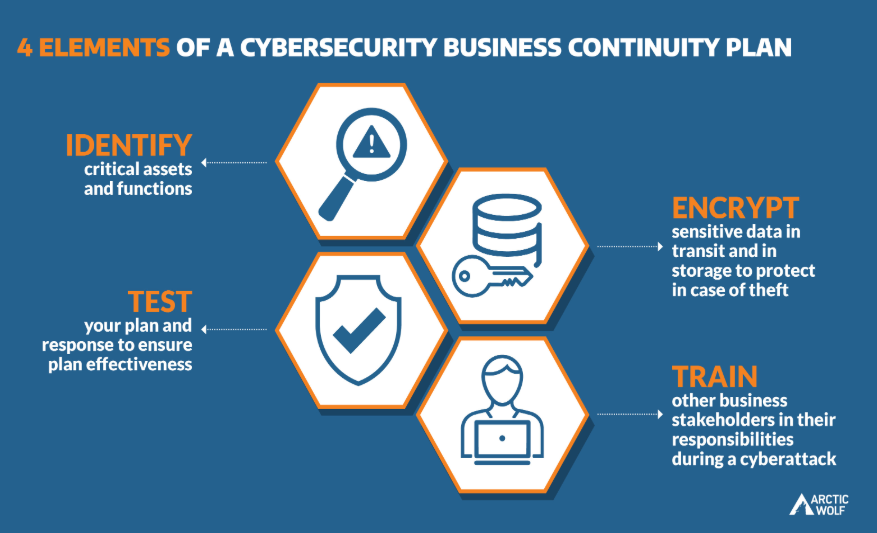
Detailed BCP Process — Seven Steps
1. Develop the BCP Policy
Define the program’s intent, scope, governance structure, and assigned roles.
Set goals, document assumptions, and gain executive approval.
Key manager questions: “Do we have management buy-in?” and “What exactly are we protecting, and why?”
Output: Approved BCP policy.
2. Conduct the Business Impact Analysis (BIA)
Identify mission-critical processes.
Determine Maximum Tolerable Downtime (MTD), Recovery Time Objective (RTO), and Recovery Point Objective (RPO).
Assess operational and financial consequences of downtime.
Key questions: “What’s the cost of downtime?” and “Which processes must recover first?”
Output: BIA report with recovery requirements.
3. Perform the Risk Assessment
Identify internal and external threats.
Evaluate vulnerabilities and map threats to business functions.
Key questions: “What could disrupt these processes?” and “Can we prevent it?”
Output: Risk assessment report.
4. Identify Recovery Strategies
Select feasible, cost-effective methods such as alternate facilities, remote work, or manual processes.
Key question: “What’s the right combination of people, technology, and location to ensure recovery?”
Output: Approved recovery strategy.
5. Develop the BCP & Recovery Plans
Document step-by-step procedures for restoring both business operations and IT services.
Include IT contingency actions, communication protocols, and evacuation procedures.
Key question: “Can a non-technical person follow this during a high-pressure situation?”
Output: Fully documented continuity and recovery plans.
6. Test, Train, and Exercise
Conduct tabletop simulations, functional tests, and full-interruption drills.
Train staff on roles and responsibilities.
Key questions: “When was this last tested?” and “Who can execute the plan effectively?”
Output: Test results and trained personnel.
7. Maintain & Review the BCP
Update the plan after incidents, audits, or major organizational changes.
Revise contact lists, resources, and strategies as needed.
Key question: “Is the plan still aligned with our current business model?”
Output: Updated, version-controlled BCP.
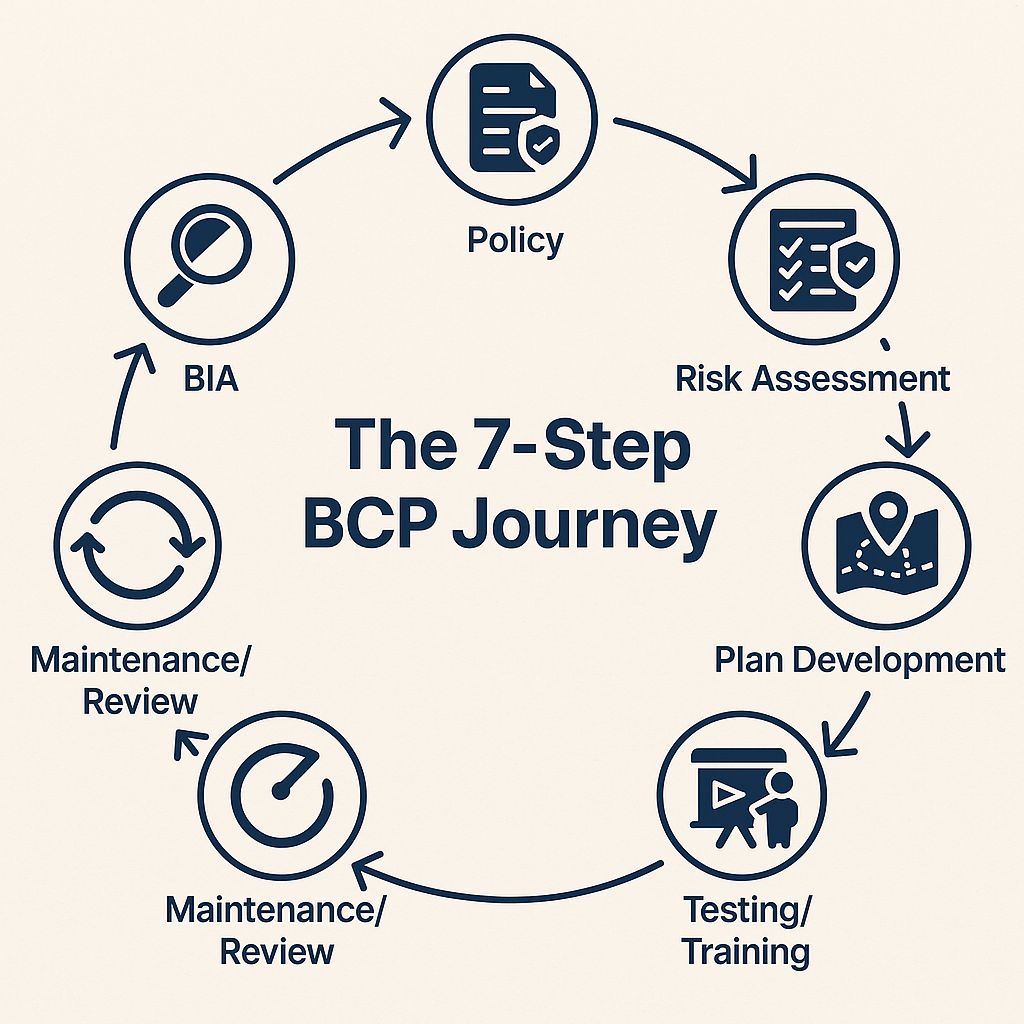
How to Create a BCP
Step 1 — Establish the BCP Policy
Serves as documented proof of senior management support.
Defines compliance obligations and regulatory requirements.
Appoint a project manager or BCP consultant to lead the process.
Step 2 — Schedule the BIA
Inventory all business processes and identify those essential for continued operation.
Collect data on dependencies, inputs, outputs, and resource requirements.
Assess financial, operational, reputational, and regulatory impact of downtime.
Define MTD, RTO, and RPO for each critical process.
Prioritize functions based on criticality.
Step 3 — Perform a Cost-Benefit Analysis
Compare the cost of downtime with the cost of proposed solutions.
Example:
A system generating $1,000/day loses $500 for each hour offline.
If downtime of 1 hour is tolerable, an expensive $10,000 recovery solution may be unnecessary.
Step 4 — Define a Good BCP
Good BCP: RTO is less than MTD.
Bad BCP: RTO exceeds MTD.
Example Timeline:
Outage starts at 11:10 AM; 40% of services restored by 11:25 AM.
Full recovery achieved by 11:30 AM, with 5 minutes of Work Recovery Time (WRT).
MTD = RTO + WRT.
Step 5 — Prioritize Recovery Strategies
Hot site for mission-critical workloads.
Warm or cold sites for lower-priority operations.
Secure funding and gain management approval before finalizing the plan.
Continuous Review
A BCP is a living document:
Review and update regularly or after any significant change in operations.
Conduct fresh BIA studies when priorities shift.
Keep DRP, contingency, and recovery plans aligned with the updated BCP.
The Four-Step BCP Process
The (ISC)² CBK framework condenses BCP into four high-level phases:
1. Project Scope and Planning
Begin with project initiation and leadership endorsement.
Define scope, objectives, and planning assumptions.
Estimate personnel and financial resources.
Set timelines and deliverables.
Form a cross-departmental BCP committee.
Consider:
The risk of not having a BCP.
The potential cost if disaster strikes.
2. Business Impact Analysis (BIA)
Identify essential services, systems, and infrastructure.
“Essential” means their loss would cause significant, potentially irreversible harm.
Produce a prioritized matrix of these services.
Use BIA to guide investment, resource allocation, and plan development.
BIA Includes:
Vulnerability and risk analysis.
Prioritization of processes.
Downtime tolerance estimates.
Financial loss projections.
Resource requirements for recovery.
BIA Should Answer:
What processes are essential?
What would be the impact of disruption?
What dependencies or single points of failure exist?
What are the recovery requirements?
Key Metrics:
WRT: Time to verify restoration.
MTD/MTO: Maximum time a process can be unavailable without severe impact. MTD = RTO + WRT or RTO + WRT < MTD.
RTO: Max acceptable outage before unacceptable impact. RTO < MTD.
RPO: Acceptable data loss point prior to disruption.
3. Continuity Planning / Contingency Strategies
Document contingency costs.
Get cost estimates for external services (RFI, RFQ, RFP).
Secure SLAs with providers.
Evaluate full-loss facility recovery strategies.
Update the Business Resumption Plan (BRP).
Present recovery strategies for approval.
4. Approval and Implementation
CEO or senior officer endorsement.
Develop an implementation guide.
Deploy resources.
Maintain the plan.
Train all relevant personnel, ensuring at least an overview for everyone.
🧠 Brain Ticklers — BCP & DRP
Q1 :During a regional outage, leadership says the customer portal must be back within 3 hours and the business cannot tolerate more than 5 hours of downtime. Which statement is MOST accurate?
A. RPO < MTD, so recovery is acceptable
B. RTO (3h) < MTD (5h), so the continuity target is feasible
C. RTO (5h) < MTD (3h), so the plan is feasible
D. WRT must equal 2 hours to meet MTD
Q2 : A fire destroys the primary data center. IT restores databases and app servers at a warm site, but the customer support team has no phones, no workspace, and no call‑routing. Which plan failed?
A. DRP — because the systems are not restored
B. DRP — because voice is an IT service
C. BCP — because non‑IT operations continuity wasn’t ensured
D. Incident Response — because the event was not contained
Q3 : You’re building the continuity program using the CBK four-step model. Which sequence is correct?
A. BIA → Approval & Implementation → Scope & Planning → Continuity Strategies
B. Scope & Planning → BIA → Continuity/Contingency Strategies → Approval & Implementation
C. Risk Assessment → BIA → Plan Approval → Training
D. Continuity Strategies → BIA → Scope & Planning → Documentation
Q4 :A trading system has RTO = 30 minutes and RPO = 10 minutes. Which combination BEST supports these targets?
A. Cold site + nightly full backups
B. Warm site + hourly snapshots
C. Hot site + synchronous replication + automated failover
D. Warm site + asynchronous replication with 2‑hour lag
Q5 : Revenue is $12,000/day (=$500/hour). A proposed solution costs $8,000/year and reduces average outage from 3 hours to 1 hour per incident. There are 6 incidents/year. Is it cost‑effective?
Current loss = 3h × $500 × 6 = $9,000/year
With control = 1h × $500 × 6 = $3,000/year
Benefit = $9,000 − $3,000 = $6,000/year
Net = Benefit − Cost = $6,000 − $8,000 = −$2,000/year
A. Yes, because ALE decreases by $6,000
B. No, because the safeguard costs more than the avoided loss
C. Yes, because RTO < MTD
D. It depends only on qualitative risk rating
Q6 :You’re kicking off a BIA. What should you do FIRST to avoid guesswork and bias in criticality ratings?
A. Draft evacuation procedures
B. Build data‑gathering instruments (interviews, questionnaires, dependency mapping)
C. Choose the recovery site type (hot/warm/cold)
D. Publish the finalized MTD, RTO, RPO list
Q7: After deploying policies, training, monitoring, and encryption, leadership asks why a contingency plan is still needed. BEST response?
A. Because controls eliminate all risks if correctly implemented
B. Because residual risks persist; contingency/IR plans address what remains
C. Because auditors always require at least one live failover per quarter
D. Because DRP alone is sufficient for enterprise continuity
Q8 : A payment processor sets MTD = 4 hours, RTO = 1 hour, RPO = 15 minutes. Which recovery posture aligns BEST?
A. Cold site + offsite tapes
B. Warm site + hourly log shipping
C. Hot site + near‑sync replication; pre‑provisioned capacity and runbooks
D. Warm site + next‑day VM restores
Follow the Series : Missed Beginning Read About CIA and Security Governance
This episode of Anya in Cybersecurity covers Security & Risk Management — part of CISSP Domain 1 preparation. Follow the full series for structured exam readiness.
